Abstract
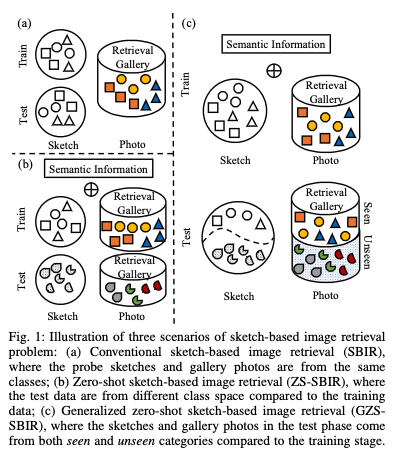
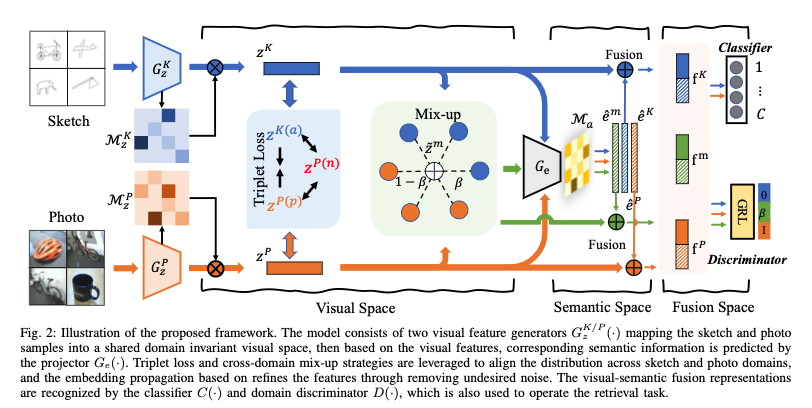
Zero-shot sketch-based image retrieval (ZS-SBIR) has attracted great attention recently, due to the potential application of sketch-based retrieval under zero-shot scenarios, where the categories of query sketches and gallery photos are not observed in the training stage. However, it is still under insufficient exploration for the general and practical scenario when the query sketches and gallery photos contain both seen and unseen categories. Such a problem is defined as generalized zero- shot sketch-based image retrieval (GZS-SBIR), which is the focus of this work. To this end, we propose a novel Augmented Multi- modality Fusion (AMF) framework to generalize seen concepts to unobserved ones efficiently. Specifically, a novel knowledge discovery module named cross-domain augmentation is designed in both visual and semantic space to mimic novel knowledge unseen from the training stage, which is the key to handling the GZS-SBIR challenge. Moreover, a triplet domain alignment module is proposed to couple the cross-domain distribution between photo and sketch in visual space. To enhance the robustness of our model, we explore embedding propagation to refine both visual and semantic features by removing un- desired noise. Eventually, visual-semantic fusion representations are concatenated for further domain discrimination and task- specific recognition, which tend to trigger the cross-domain align- ment in both visual and semantic feature space. Experimental evaluations are conducted on popular ZS-SBIR benchmarks as well as a new evaluation protocol designed for GZS-SBIR from DomainNet dataset with more diverse sub-domains, and the promising results demonstrate the superiority of the proposed solution over other baselines. The source code is available at https://github.com/scottjingtt/AMF GZS SBIR.git.

Citation
If you think this work is interesting, feel free to cite
1
2
3
4
5
6
7
8
9
@article{jing2021augmented,
title={Augmented Multi-Modality Fusion for Generalized Zero-Shot Sketch-based Visual Retrieval},
author={Jing, Taotao and Xia, Haifeng and Hamm, Jihun and Ding, Zhengming},
journal={IEEE Transactions on Image Processing},
volume={},
pages={},
year={2022},
publisher={IEEE}
}
Reference
[1] Jing, Taotao, Haifeng Xia, Jihun Hamm, Zhengming Ding. “Augmented Multi-Modality Fusion for Generalized Zero-Shot Sketch-based Visual Retrieval.” IEEE Transactions on Image Processing (2022).