Abstract
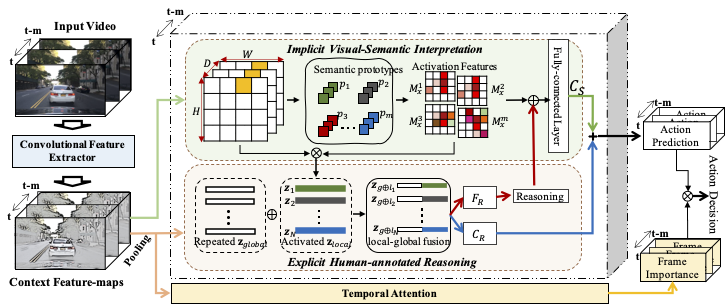
Autonomous driving attracts lots of interest in interpretable action decision models that mimic human cognition. Existing interpretable autonomous driving models explore static human explanations, which ignore the implicit visual semantics that are not annotated explicitly or even consistent across annotators. In this paper, we propose a novel Interpretable Action decision making (InAction) model to provide an enriched explanation from both explicit human annotation and implicit visual semantics. First, a proposed visual-semantic module captures the region-based action-inducing components from the visual inputs, which automatically learns the implicit visual semantics to provide a human-understandable explanation in action decision making. Second, an explicit reasoning module is developed by incorporating global visual features and action-inducing visual semantics, which aims to jointly align the human-annotated explanation and action decision making in a multi-task fashion. Experimental results on two autonomous driving benchmarks demonstrate the effectiveness of our InAction model for explaining both implicitly and explicitly by comparing it to existing interpretable autonomous driving models.
Framework
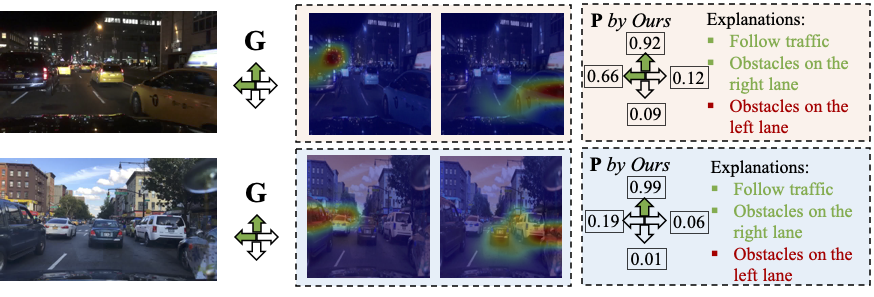
Explicit Human-annotated Explanation

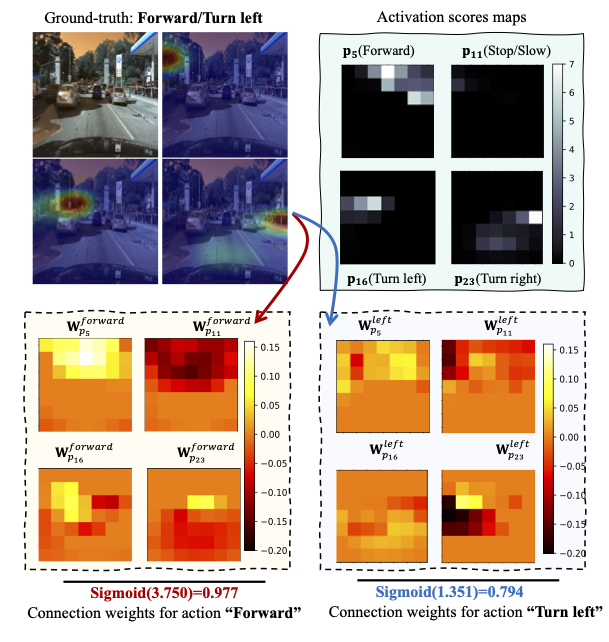
Visualization of Learned Prototypes

Implicit Visual-Semantic AND Explicit Human-annotated Explainable Action Prediction
Visualization of Reasoning Process via Learned Prototypes Activation
Citation
If you think this work is interesting, feel free to cite
1
2
3
4
5
6
7
8
@InProceedings{jing2022inaction,
author = {Jing, Taotao and Xia, Haifeng and Tian, Renran and Ding, Haoran and Luo, Xiao and Domeyer, Joshua and Sherony, Rini and Ding, Zhengming},
title = {InAction: Interpretable Action Decision Making for Autonomous Driving},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
month = {October},
year = {2022}
}
Reference
[1] Jing, Taotao, Haifeng Xia, Renran Tian, Haoran Ding, Xiao Luo, Joshua Domeyer, Rini Sherony, and Zhengming Ding. “InAction: Interpretable Action Decision Making for Autonomous Driving” In Proceedings of the European Conference on Computer Vision (ECCV), 2022.